Страничная организация памяти
Страничная организация памяти
В данной статье мы рассмотрим следующие вопросы:
Инструменты управления памятью:
- Страничная организация памяти (также таблицы страниц)
- Сегментная организация пямяти (таблицы сегментов)
- Страничное прерывание (page fauet) и виртуальная память
- Механизмы замещения страниц: Алгоритм Belady, FIFO Алгоритм LRU (Last recently used) – наименее используемое, Not Frequently Used (алгоритм clock – часовой)
- Рабочее множество
- Алгоритм Page Fault Frequency
Страничная организация памяти
Организация памяти в виде страниц борется с двумя проблемами:
- Внешней фрагментацией – используются блоки фиксированного размера в виртуальной и физической памяти, т.е. все запросы на выделение памяти будут кратны, не будет оставаться некратных зон.
- Внутренней фрагментацией – блоки достаточно малого размера, поэтому (К) будет мал.
С точки зрения программиста:
- Процессам виртуальное адресное пространство предоставляется непрерывным, от байта 0 до байта N;
- N зависит от аппаратной поддержки (например 32бита — адрресное пространство 4Гб), делится соответственно.
- В реальности виртуальные страницы распределены по страницам физической памяти далеко не непрерывно и не один к одному. Это два разных мира – физические страницы и виртуальные страницы. Это ключевой аспект, который надо понимать.
С точки зрения менеджера памяти:
- Эффективное использование памяти из-за очень низкой внутренней фрагментации.
- Внешняя фрагментация полностью отсутствует и не нужно дефрагментировать.
С точки зрения защиты:
- Процесс имеет доступ только к своему адресному пространству.
Допущение – все страницы виртуальной памяти всегда находятся в страницах физической памяти.
Не будем думать, что есть только виртуальные страницы, а физических – их нет, т.е. полное отображение виртуальной и физической памяти.
Предположим, что все страницы резидентно в памяти, это необходимо, чтобы понять как работает трансляция адресов.
Трансляция адресов
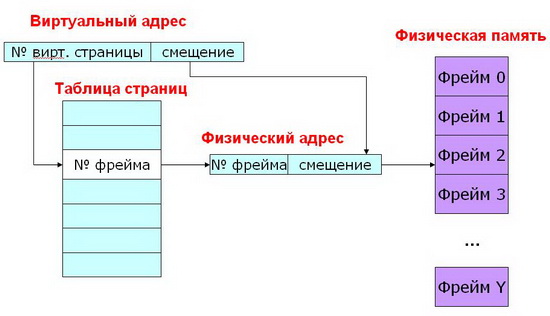
Трансляция виртуального адреса: Виртуальный адрес состоит из двух частей: номер виртуальной страницы (VPN) и смещение внутри страницы
Номер виртуальной страницы (VPN- virtual page number) это индекс в таблице страниц (Pagetable).
Запись в таблице страниц (PTE – page table entry) содержит номер фрейма (PFN –page frame number).
Номер фрейма – это номер физической страницы.
Фрейм – это страница физической памяти.
Смысл таблицы страниц – одна запись в таблице страниц (PTE) на одну страницу виртуального адресного пространства (VPN), отображает VPN на PFN.
Какая виртуальная страница соответствует какому фрейму физической памяти.
Трансляция адресов
Есть виртуальный адрес, состоящий из двух частей:
- №виртуальной страницы, по нему идет поиск в таблице страниц и находится № фрейма, он составляет одну часть физического адреса;
- Смещение – берется напрямую – вторая часть физического адреса.
По новому адресу осуществляется поиск уже в физической памяти и доступ к данным.
На рисунке ниже каким образом два процесса располагаются в памяти.

страничная организация памяти
Существуют два процесса 0 и 1, у 0 есть две страницы у 1 процесса четыре страницы. И мы видим, что они могут отображаться как угодно, вплоть до того, что две виртуальные страницы могут отображаться на одной физической.
Зачастую это бывает полезно, простор для манипуляций ограниченный и в этом состоит вся прелесть виртуального адресного пространства.
Страничная организация памяти — Пример
-32битная разрядность адресов
-Размер страницы 4096байт
-VPN длиной 20бит, смещение 12бит (20+12=32бита)
-Преобразуем виртуальный адрес 0* 43456 323
— № вирт. страницы смещение внутри страницы
-VPN=43456 смещение=323
-Допустим, что в ячейке таблицы страниц по индексу 0*43456 находится значение фрейма PFN= 0*1002.
Получаем физический адрес 0*01002323
Таблица страниц (PTE)
Если есть таблица страниц, которая содержит преобразование адреса, то необходимо воспользоваться и нагрузить ее дополнительными функциями:
- Добавить защиту доступа;
- Добавить дополнительную вспомогательную информацию (например, используется эта вирт.страница или нет, был ли к ней когда-либо осуществлен доступ, была ли в нее осуществлена запись…);
Таблица страниц превращается в сложную структуру данных, которые начинает использоваться множеством всяких дополнительных полей.
Все это нужно, чтобы сохранить память для других процессов, делать все быстро и не плодить десятки новых таблиц с данными – все по возможности хранить внутри таблицы РТЕ.
Приведем пример стректуры таблицы страниц PTE.

таблица страниц PTE
Если мы посмотрим на запись в РТЕ, то мы увидим, что туда можно поместить:
- V— может ли использоваться данная запись РТЕ (valid or not) – бит валидности, бит присутствия;
- R- был ли доступ к этой странице;
- M– была ли страница модифицирована;
- P– какие операции разрешены (битовая маска операций);
- PFN– номер фрейма (как основной, как основная нагрузка).
Преимущества страничной памяти
- Легко выделять физическую память
— Списки свободных фреймов, выделить фрейм
– просто удалить из списка свободных; — Внешняя фрагментация не проблема, т.к. фреймы одного размера; - Естественный подход
— Всей программе не нужно быть резидентной – это «побочный» продукт;
— Все страницы одного размера;
— Основа – устранение внешней фрагментации.
Недостатки страничной памяти
- Внутренняя фрагментация
— Процессам может быть нужны размеры, некратные размеру страницы;
— По сравнению с размером адресного пространства, размер страницы очень мал. - Накладные расходы при обращении к памяти
– вначале к таблице страниц, а затем уже к памяти.
Решение: аппаратный КЭШ для обращений к таблице страниц (TLB translation lookaside buffer – буфер внутри процессора). - Большой объем памяти, требуемый для хранения таблиц страниц.
Один РТЕ на одну страницу в виртуальном адресном пространстве
Пример:
Архитектура х86
32-битное АП с 4КБ страницами = 2 в 20 степени РТЕ= 1048576записей РТЕ
4 байта на РТЕ = 4Мб памяти на таблицу страниц.
В ОС создаются отдельные таблицы страниц для каждого процесса.
Итого, например 25процессов * 4Мб = 100Мб
Соответственно нужны отдельные таблицы страниц для каждого процесса.
Решение: хранить таблицы страниц в страничной памяти)
Страничная организация памяти (обобщение)
- Решает разные проблемы, типа фрагментации
- Адресное пространство – линейный массив байтов
- Разделяется на страницы одинакового размера (например 4Кб)
- Использует таблицы страниц для отображения виртуальной страницы на физический фрейм
Сегментное распределение памяти (Сегментация)
Сегментация подходит к распределению памяти более «продвинуто», чем страничная — выделяются разные логические сегменты памяти: стек, код программы, куча, т.е. адресное пространство делится на логические блоки.
Блоки имеют свой размер, расположение и права доступа, например, куча – для динамической памяти программы – все это отдельные логические блоки памяти.
Их не нужно мешать в одно, поэтому следующим этапом было разделение всего названного и ввод виртуального адреса в виде пары: Сегмент, смещение.
Виртуальный адрес в виде – сегмент + смещение.
Страничная организация предполагает куски памяти, как в примере выше, 4096байт (4Кб), таких кусков можно брать сколько угодно.
Сегментация:
- Позволяет разделить разные участки памяти в соответствии с их назначением
- Динамический (изменяемый) размер у сегментов
Два варианта
- Один сегмент на процесс – переменный раздел
- Много сегментов на процесс — сегментация
Аппаратная поддержка сегментации
- Одна пара база-предел(лимит) на сегмент
- Сегменты идентифицируются №, который является индексом в таблице
- Виртуальный адрес = пара <СЕГМЕНТ, СМЕЩЕНИЕ>
- Физический адрес = база сегмента + смещение
Недостатки:
- Все недостатки, присущие организации памяти разделами переменной длины присущи и сегментной организации
- Внешняя фрагментация
Лучшим, как можно заметить является организация этих подходов в один. Давайте объединим страничную и сегментную адресацию.
Архитектура х86 поддерживает и страничную и сегментную адресацию.
- Сегменты используются для управления логическими блоками, обычно сегменты большие (помещают множество страниц).
- Сегменты разбиваются на страницы, у каждого сегмента своя таблица страниц
В современных ОС достаточно ограниченно применяются сегменты, много их не применяется. Пример ОС Linux
- Один сегмент кода ядра, Один сегмент данных ядра
- Один сегмент кода пользователя, Один сегмент данных пользователя
- Все сегменты организованы странично.
Страничная виртуальная память
Мы предполагали ранее, что вся память резидентная — не рассматривался вариант, что какой-либо страницы может не быть в физической памяти.
Сейчас, допустим, что адресное пространство может и не быть полностью резидентным. На практике так в основном и есть – память никогда не резидентна. Процессов сотни, на них выделяется много виртуальной памяти и ее не хватит на отображение в физической памяти.
Например, 100 процессов 100П*4Гб=400ГБ ОП.
Соответственно какая то часть адресного пространства находится в физической памяти, какая то часть в некоторой вторичной памяти (понимается дисковая подсистема), абстрагируется от физической реализации.
С точки зрения опрерационной системы важно, что ОС использует основную память, как КЭШ.
У ОС есть медленная память (это дисковая подсистема), она может туда загружать процессы и выгружать их оттуда, а основная память используется как ограниченный ресурс, сродни классическому кэшированию.
Принцип работы достаточно простой – нужная страница перемещается в свободный фрейм физической памяти из вторичной памяти. А если свободных фреймов нет, то какая-либо страница выгружается на диск, таким образом освобождается драгоценный фрейм физической памяти.
Важно отметить, запись во вторичной памяти происходит только тогда, когда страница в основной памяти была модифицирована, если она не была модифицирована, то соответственно и выгружать нечего.
Весь процесс происходит прозрачно для программы. Никакая программа не управляет напрямую, какую страницу ей выгрузить в основную память, какую загрузить.
Менеджер памяти операционной системы все абстрагирует и делает все прозрачным для программиста, чтобы он не «напрягался» на данную тему, это сложно реализовывать самостоятельно.
Рассмотрим понятие Страничное прерывание.
Page fault – Страничное прерывание
Процесс обращается к виртуальному адресу на выгруженной (или загруженной) странице, т.е. страница в принципе отсутствует, при этом обращении и происходит страничное прерывание. Как этот процесс весь работает:
- Когда страница выгружается, ОС устанавливает бит присутствия (valid – является ли валидной ячейка) PTE=0. И там же в РТЕ записывает куда она была соответственно выгружена.
- Когда же процесс обращается к этой странице, то происходит исключение, т.к. Valid=0,т.е. бит валидности установлен в 0 – страница не использовалась.
- После того, как произошло исключение ОС передает управление обработчику страничного прерывания
- Обработчик находит то место, куда была выгружена страница
- Считывает эту страницу в фрейм физической памяти, обновляет РТЕ, ставит бит валидности (присутствия) в 1.
- В физической памяти появляется новая страница.
Процесс достаточно простой, если страницы нет, то сама же ОС ее загрузит обратно, или выгрузит, когда ей это надо.
Загрузка по требованию
Еще один ключевой механизм работы менеджера памяти.Практически все страницы памяти загружаются по требованию.
Смысл: страницы загружаются в основную память только тогда, когда к ним происходит непосредственное обращение.
Предсказать заранее, какая страница потребуется в будущем – сложно(это как гадать на кофейной гуще).
Сегодня для этого разработано множество алгоритмов, есть разные подходы. Самый логичный из них — кластеризация страниц.
Операционная система ведет учет страниц, которые обычно загружаются вместе, даже если они расположены в различных местах виртуальной памяти или физической памяти. Если идет обращение к одной их них, то ОС загружает все страницы их этого кластера.
Это естественный подход к тому, как можно провести исходную оптимизацию этого алгоритма. Можно даже предоставить программисту возможность определять такие кластеры.
Механизм замещения страниц
Допустим у нас заняты все фреймы(страницы) физической памяти, а нам нужно еще загрузить одну страницу.
Вопрос – какую из страниц физизической памяти выгрузить? Ведь страниц много и это выбора многое зависит.
Алгоритм замещения страниц простой:
- Выбрать страницу, которую не понадобится в ближайшем бедующем
- Выбрать страницу, которая не была модифицирована, чтобы обойтись без записи ее на диск.
- Чтобы обойтись без замены в ОС есть пул свободных страниц.
Но проблема замещения страниц существует. Посмотрим последовательность действий в ОС, когда у нас загружается программа.
Как загружается программа:
- Для создания нового процесса создается новый РСВ (процесс контрол.блок).
- Создается таблица страниц для этого процесса, которая описывает его виртуальное адресное пространство.
- Образ программы на диск размещается блоками в адресное пространство (он не копируется, а неким образом размещается).
- Строится таблица страниц, указатель на которую уже есть в РСВ. — Все РТЕ имеют бит присутствия =0 (виртуальное адресное пространство в начале процесса полностью пустое, в плане отображения на физическую память – ни одна страница не присутствует) — В эти же РТЕ заносится информация о нахождении этих физических страниц уже во вторичной памяти, т.е. на диске
- Передает управление на точку входа этого процесса – исполнение первой же инструкции приводит к страничному прерыванию (page fault).
- Обработчик прерывания загружает эти страницы из дисковой памяти.
Таким образом никто, ничего заранее не подгружает, все загружается через «page fault» по требованию. Именно так все работает.
Алгоритмы замещения страниц
Принцип локальности определяется двумя подходами:
- Одна загрузка –много обращений (локальность по времени);
- Обращение к страницам рядом с уже загруженной (локальность по расположению).
Загрузка страниц по требованию может быть частой, а может и не такой частой, зависит от:
- Локальности;
- Политики замещения страниц;
- Объема физической памяти;
- «рабочего множества» ( так называемого).
Смысл алгоритма замещения страниц – уменьшить число страничных прерываний (page fault) путем выбора лучшей страницы для выгрузки.
Лучшая – та, к которой вообще больше не будет обращений, т.е. освобождает место в памяти и решаем все вопросы, все будет работать быстро.
Далее рассмотрим разные алгоритмы, которые были предложены к решению данной проблемы (фундаментальной и основополагающей, как оказалось). Это как в алгоритмах планирования, они существенно влияют на производительность, отзывчивость системы. В менеджере памяти тоже есть ниша, которая оказывает большое влияние.
Алгоритм Belady
Оптимальность его доказана по критерию наименьшего числа страничных прерываний.
—Выгрузить страницу, которая дольше всех не будет использоваться в будующем. Проблема – предсказать будущее. Физический смысл Алгоритма Вelady(АВ) на практике реализовать сложно, а по сути нельзя. Его используют в качестве эталона для сравнения.
Если Вы реализовали какой-то другой алгоритм практически в операционной систем и он оказался ненамного хуже, чем АВ, что значит Вы сделали очень хороший алгоритм.
Но на самом деле не существует «лучшего» алгоритма, т.к. все зависит от задачи. Например, при планировании при интерактивных процессов один алгоритм, для фоновых – другой. Чаще используется объединение этих всех алгоритмов.
Не существует худшего алгоритма, но в качестве эталона «худшего» можно указать: — Случайный выбор страницы для замены, но случайный не всегда худшее.
Рассмотрев теоретический АВ первым был сделан алгоритм FIFO.
Алгоритм FIFO
Достаточно прост в реализации:
—При загрузке страницы мы помещаем ее в конец списка
—Выгружаем страницы из начала списка.
Преимущества:
- Выгружается самая старая страница, может быть и редко использованная
Недостатки :
- Выгруженная страница может все еще использоваться, хотя и давно загрузилась, нет уверенности что она редко используемая.
- Плохая производительность
Аномалия Belady
Существует понятие аномалия Belady – если дать процессу больше физической памяти, то определенные последовательности обращений к страницам приведет к увеличению числа страничных прерываний.
Есть определенная ограниченная физическая память, когда выполняется процесс он генерирует страничные прерывания. При использовании алгоритма FIFO при определенных случаях, если увеличить размер физической памяти, то этих страничных прерываний станет еще больше. Это доказал Belady и названо явление аномалией Belady.
Алгоритм LRU (Last recently used) – наименее используемое
Использует информацию об обращениях к страницам памяти для принятия решения о ее выгрузке.
Смысл: угадать будущее на основе прошлого.
При завершении выгрузить ту страницу, которая дольше всех не использовалась.
При сравнении с АВ, то АВ заглядывает в будущее, LRU в прошлое.
В идеале нужно сохранять время при каждом обращении к памяти в РТЕ, сортировать на основе этих данных. И та страница, к которой дольше всех не было обращений выбирается первым кандидатом на выгрузку.
Если каждое обращение к памяти будет сопровождаться записью значения времени последнего обращения к памяти, то система начнет тормозить. Преимущество LRU сойдет на нет, все окажется слишком долго.
На практике LRU «в чистом виде» не реализуется. Но существуют аппроксимации, спасает математический подход ко всему, можно реализовать различные приближения к алгоритму LRU.
Аппроксимации алгоритма LRU
Существует бит в РТЕ, который называется referenced (0 или 1). Вводим счетчик для каждой страницы. Алгоритм аппроксимации: регулярно для каждой страницы через какие-то равные промежутки времени смотрим:
- если бит referenced =0, то мы увеличим некий счетчик;
- если бит referenced =1, то счетчик обнулим.
И через равные промежутки времени всегда обнуляем бит referenced.
Таким образом, эта аппроксимация приводит к тому, что счетчик будет содержать количество временных интервалов с момента последнего обращения к памяти к этой странице.
В некоторых архитектурах этого бита в РТЕ нет, поэтому применяются всякие «некрасивые» ухищрения. Бит referenced устанавливается автоматически процессором, когда происходит доступ к памяти, чтобы было достаточно быстро.
Not Frequently Used — алгоритм clock – часовой
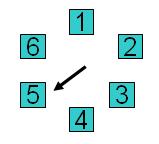
Алгоритм часов
Суть Алгоритма: он замещает достаточно старую страницу. Фреймы физической памяти организуются в виде часов. Есть часовая стрелка и по кругу фреймы физической памяти. Стрелка выбирает кандидата на выгрузку.
- Если бит ref=0, то выгружает эту страницу
- Если бит ref=1, то обнуляет его и идет дальше
- Действия происходят через регулярные промежутки времени.
Если памяти много, то ниже затраты и ниже точность.
Изначально в список «часов» помещаются только те страницы, которые используются, то есть те у которых ref=1. Стрелка идет по кругу и начинает обнулять ref и соответственно выгружать страницы при необходимости. Поэтому из круга выпадают только те, которые не были недавно использованы.
Задача: Распределение фреймов физической памяти между процессами
Существуют два подхода
- Локальный алгоритм замещения
— У каждого процесса свой лимит на число страниц, который он может использовать
— Выгружает только свои страницы - Глобальный алгоритм замещения
— Неважно, чьи страницы кому принадлежат – алгоритм замещения идет по большому кругу и выгружает независимо от владельца.
Примеры из практики:
Linux использует глобальное замещение.
Существуют гибридные алгоритмы – локальное замещение и механизм явного добавления/удаления фреймов.
Рабочее множество
Рабочее множество — Woking set– необходимо для моделирования локальности использования памяти.

Peter Denning
Рабочее множество – это множество тех страниц процесса, которые ему сейчас нужны.
Формальное определение РМ ввел Петр Деннинг в 1968г.
Эти алгоритмы используются во всех современных ОС.
WS(t,w) ={страницы Р, к которым были обращения за интервал (t-w; t) }
t- время;
w — окно рабочего множества;
«Сейчас» — в определении рабочего множества это имеет какую-то точку во времени, «когда сейчас?» и имеет некоторую длительность.
Страница находилась в рабочем множестве тогда, когда к ней обращались за последние W-единиц времени.
Рабочее множество (WS) изменяется во времени и размер WS также меняется, это плавающие величины.
Размер рабочего множества
Введем обозначение |WS(t,w)| — зависит от локальности
При плохой локальности, подгружается много страниц.
|WS(t,w)| в этот момент увеличивать
Очевидно, что WS должно быть в памяти резидентно, иначе случится «пробуксовка»(trashing), компьютер затормаживается, т.е. постоянные страничные прерывания для того, чтобы подгрузить страницу, так как процесс без нее работать не сможет, он будет к ней обращаться.
Перед тем как запустить процесс мы должны оценить размер его исходного рабочего множества.
- Оценить |WS(0,w)| для процесса;
- Запустить этот процесс только тогда, если есть столько фреймов физической памяти, чтобы туда поместилось это исходное рабочее множество;
- Используя алгоритм замещения страниц загружать нужные страницы;
- Динамически отслеживать размеры рабочего множества процессов.
Алгоритм Page Fault Frequency
Page Fault Frequency – частоты возникновения страничных прерываний.
Он в корне отличается от всех остальных, так как пытается уровнять число страничных прерываний между всеми процессами и снизить их общее число.
За счет чего он это делает?
- Следит за частотой страничных прерываний каждого процесса
- Если оно выше определенного порога – предоставляет процессу больше памяти
- Если оно меньше, то забирает у него память.
- Таким образом он перераспределяет память между процессами и регулирует число страничных прерываний.
И последнее, что мы рассмотрим это пробуксовка.
Пробуксовка (thrashung)
Она происходит, когда система проводит большую часть времени, обслуживая страничные прерывания, а не занимаясь полезной работой – вычислениями.
Из-за чего это происходит, причины:
- Из-за неправильного алгоритма замещения страниц при достаточном объеме памяти;
- Либо если объема физической памяти недостаточно, слишком много активных процессов ;
Это ненормально состояние, которое должно решаться каким-то образом.
Скачать презентацию к лекции «Управление памятью»
Скачать тест по теме «Управление памятью»
Очень понравилась статья, но тем не менее у меня тоже есть своя точка зрения
по этому поводу. Поэтому добавлю в избранное и посмотрю дальнейшие комментарии
Достаточно интересная статья. Думаю стоит добавить в избранное для дальнейшего изучения
Интересно. Вопрос только в том, как это будет выглядеть в будущем 🙂
Круто..взяла почти все))
Блог интересный, добавил в закладки.